
デジタルペンテストサービス部の魚脳です。
今回はiOS内部ストレージの中、たまにどっかに隠れているbplistファイルの構造やそれを引っ張り出す方法のまとめとなります。
bplistとは
まずplistとは
プロパティリストの略であり、macOS Cocoa・NeXTSTEP・GNUstep などで利用されるオブジェクトシリアライゼーションのためのファイル形式であります。
iOSの開発経験がある方なら、きっと馴染みがあると思います。
一方、bplistというはその文字通りバイナリ化(b)したplistを指します。xml形式のplistと比較してそのまま読めず、〇〇.plistのようなファイル(Info.plistなど)になったり、他のファイルに「隠れる」など少し厄介な存在です。
なぜbplistをターゲットに
理由としては主に2つあります
- 1つ目はbplistはplistの延長線上にあり、重要情報が保存される可能性が十二分あるため、フォレンジックやアプリ診断中に突然遭遇する事もケースによってあります。
- 2つ目は現状複数種類のファイルに含まれることを確認したため、それを一貫にして抽出できるツールがあったら良いと思いました。
上記理由は建前で、本音を言うと何回か遭遇した結果、興味が湧いたのでまとめることにしました。
解決策
一貫してbplistを抽出するために、「ここからここまではbplist」というのをきっちり把握する必要があると考え、とりあえずはbplistのフォーマット1を調べました。
bplistの構造
<plist> <dict> <key>Description</key> <string>Hello World</string> <key>flight info</key> <array> <dict> <key>flight number</key> <string>1234</string> <key>isArrived</key> <true/> <key>arriveAt</key> <date>2021-11-13T18:00:00Z</date> </dict> <dict> <key>flight number</key> <string>1111</string> <key>isArrived</key> <false/> <key>arriveAt</key> <date>2021-11-13T19:00:00Z</date> </dict> </array> <key>airport</key> <string>tokyo</string> </dict> </plist>
上記のplistをplistutilを使って変換したbplist大まかな構造(セグメント)は以下のようになります。
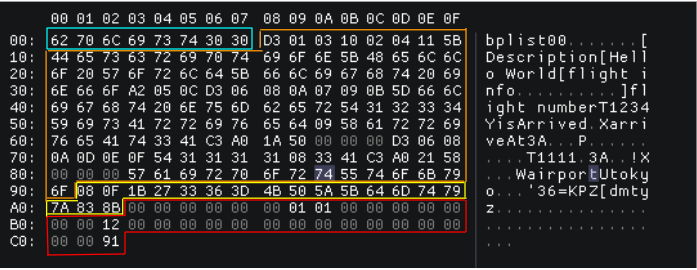
header(青色)
magic numberはbplist00固定
objects(オレンジ色)
実際のデータ部。基本はマーカー(型+データの長さ)の後ろにデータが配置されるような形になります
例えばobject5B 44 65 73 63 72 69 70 74 69 6F 6Eに対して、先頭の5Bはマーカーであり、11(0xB)文字のASCII文字列(0x5)を指します。マーカーに次ぐ11byteはそれぞれDescriptionのASCII値となります。
文字列以外に数字やブール型など型が存在しますが、このセグメントは特にbplistファイルの特定に貢献しないため、今回は割愛します。詳細はリファレンス2 を参考してください。
offset table(黄色)
このセグメントにはobject各々のオフセットが保存されます。例えば図に示したように、2番目のobject5B 44 65 73 63 72 69 70 74 69 6F 6Eのオフセットは0Fになります。オフセットのバイト数はデータ量に応じて変わります(1byteは0xFFのオフセットまでしか表せないため)。
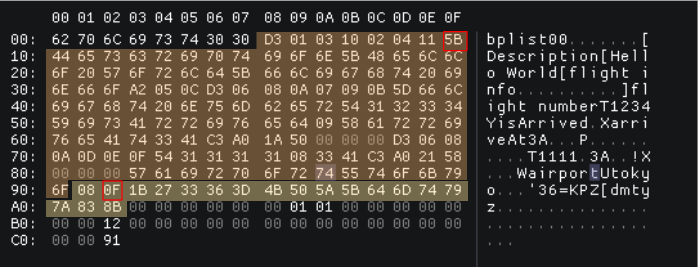
このセグメントも特にbplistファイルの特定に貢献しないため、割愛します。
trailer(赤色)
このセグメントは以下の情報を含めます、長さは32byte固定
- padding
- byte1-5
- パディング
- sort_version
- byte6
- ソート関連
- offset_table_offset_size
- byte7
- オフセットのバイト数を決めます。
- object_ref_size
- byte8
- objectが辞書型などデータが更に複雑になる場合必要なオフセットのバイト数、今回特に出番がないため、詳細を割愛します。
- num_objects
- byte9-16
- objectの個数。
- top_object_offset
- byte17-24
- offset table内最初になるのはどれかを決めます、通常は
0になります。
- offset_table_start
- byte25-32
- offset tableのオフセット。
使えそうな情報は全部trailerに詰まっているという印象でした。
抽出
長さの計算
上記の構造からheaderとtrailer以外のセグメントの長さは可変であるため、まずそれを解決しないといけません。
幸い、trailerに含まれる情報がそれを教えてくれました。

- offset_table_startは間接的に
header+objectsで長さを示します。 - offset_tableの長さは
offset_table_offset_size*num_objectで得られます。
上記によってbplistファイルの長さを計算する式はこうなります
len = offset_table_start + offset_table_offset_size*num_object + 32
例のbplistのtrailerをパースしてみると
offset_table_startは0x91offset_table_offset_sizeは0x1num_objectは0x12
公式によって長さは0x91+0x1*0x12+0x20=0xC3になり、実際の数値と一致します。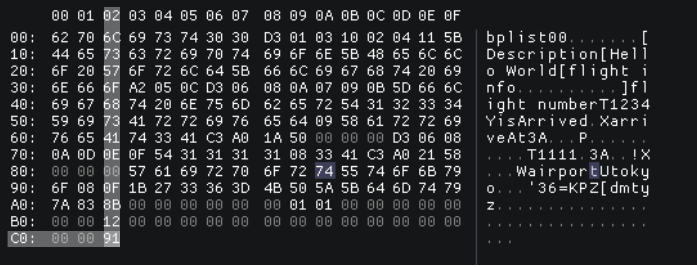
長さは(末尾のインデックス)0xC2+1=0xC3
trailerの位置から逆算
長さはtrailerから計算できるため、末尾の位置からbplistの長さ分を引けば、ファイル先頭の位置に戻れるはずです。そこから先頭の8byteがmagic numberと一致すればOKです。
よって、bplistの特定手順は以下のようになります
- 連続の32byteを仮のtrailerに見立てパースする
- パースした結果から仮の長さ
Lを計算する - 末尾から
Lbyte分を引き、その位置からの新しい8byteはmagic numberと比較して、ファイルの先頭を決める 手順3に満たす32byteを総当りする 以下はその実装の例3 になります
# -*- coding: utf-8 -*- import struct import sys def parser(data,base): # 32byteをtrailerに見立ててパースする # https://github.com/nabla-c0d3/iphone-dataprotection/blob/572dd5cd8c07f5f14f7ea9488041031dd22a26bb/python_scripts/util/bplist.py#L212 offset_size, object_ref_size, number_of_objects, top_object, table_offset = struct.unpack('!6xBB4xI4xI4xI', data[base:base+32]) # bplistファイルの長さを計算する size = 0x20 + offset_size * number_of_objects + table_offset # 先頭の位置を計算する start = base - (size - 0x20) try: # 先頭から8byteはmagic numberと一致するかどうか if data[start:start+8] == b"bplist00": with open(str(hex(start))+".bplist","wb") as f: f.write(data[start:start+size]) return else: return except: print("error") return args = sys.argv print(args[1]) with open(args[1],"rb") as f: fdata = f.read() print("size is {}".format(str(len(fdata)))) for idx in range(len(fdata)-32): # 32byteずつ総当りする parser(fdata,idx)
テストと問題点
テストとして、よくbplistを含むCache.dbを対象にbplistファイルを抽出してみます。
$ strings Cache.db|grep -i "bplist00" |wc -l //Cache.db内のbplistの概数 572 $ python3 bplistExtractor.py Cache.db //抽出 Cache.db size is 1585152 $ find -name "*.bplist"|wc -l //抽出したbplistの個数 558 $ hexdump -C 0x313f2.bplist |head -n 3 //抽出できたファイル 00000000 62 70 6c 69 73 74 30 30 d2 01 02 03 04 57 56 65 |bplist00.....WVe| 00000010 72 73 69 6f 6e 55 41 72 72 61 79 10 01 a7 05 0a |rsionUArray.....| 00000020 0b 0c 0d 20 21 d2 06 07 08 09 5f 10 10 5f 43 46 |... !....._.._CF| $ hexdump -C Cache.db|grep -i -A 3 "00313f0" //Cache.db内と同じ内容を確認 000313f0 00 00 62 70 6c 69 73 74 30 30 d2 01 02 03 04 57 |..bplist00.....W| 00031400 56 65 72 73 69 6f 6e 55 41 72 72 61 79 10 01 a7 |VersionUArray...| 00031410 05 0a 0b 0c 0d 20 21 d2 06 07 08 09 5f 10 10 5f |..... !....._.._| 00031420 43 46 55 52 4c 53 74 72 69 6e 67 54 79 70 65 5c |CFURLStringType\|
今回紹介した方法を利用して558個のbplistファイルをCache.dbから抽出できましたが、その数はCache.db内に存在するbplistのマジックナンバーの個数に下回ります。
理由としてはおそらくデータの欠損だと思います。この抽出方法はbplistのtrailer(セグメント)に依存するため、もしtrailerに欠損があるとうまく抽出できません。また、今回は「平文の状態で保存されたbplist」をターゲットにした抽出方法を紹介しましたが、暗号化やエンコードなどかかった場合は先にそれらを解決する必要があります。
まとめ
今回はbplistの構造を勉強して、最終的にそれを抽出する方法を考えました。実用シーンが限られますが、なにかの参考になれたら幸いです。
リファレンス
[1]CFBinaryPList.c
[2]Understanding Apple’s binary property list format | by Christos Karaiskos | Medium
[3]try to extract binary plist from other files · GitHub