※こちらの記事は2020年11月5日公開note版「ラック・セキュリティごった煮ブログ」と同じ内容です

こんにちは
サイバー・グリッド・ジャパン 次世代セキュリティ技術研究所のひよっこデータサイエンティスト、ささかまです。
CDLEハッカソン2020 予測性能部門で行われた、AIの精度を競うコンペティション(以下、コンペという)に参加し、入賞しました。しかし、あまり時間をかけられなかったため、ほとんど試行錯誤できませんでした。ということで、当コンペで入賞したモデルは本当に優秀なのか、時間をかけたら精度は上がったのか、検証しました。
コンペ内容
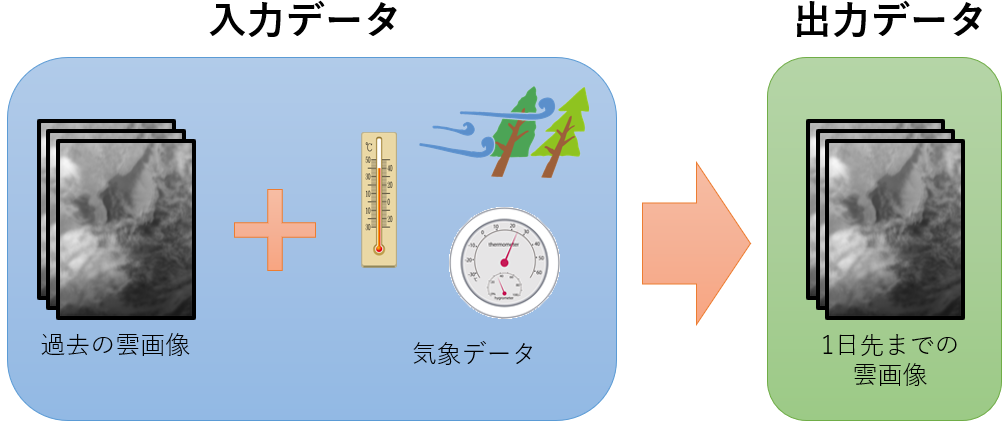
当コンペの内容を一言でいうと、「雲画像の予測」です。
過去4日分の気象衛星ひまわり8号により撮影された雲画像データと気象データ(気圧、温度、湿度、風など)を基に、その先1日分(1時間毎24枚)の雲画像を生成するAIを作成し、そのAIが生成した画像の精度を競います。精度の評価値はSSIM(Structural Similarity:構造的類似性)というアルゴリズムで計算します。値の範囲は0~1、大きいほど精度が高い(正解と近い)ことを示します。
コンペの詳細はこちらをご覧ください。
解法
私が採用した手法はU-Netをベースにしたニューラルネットワークです。
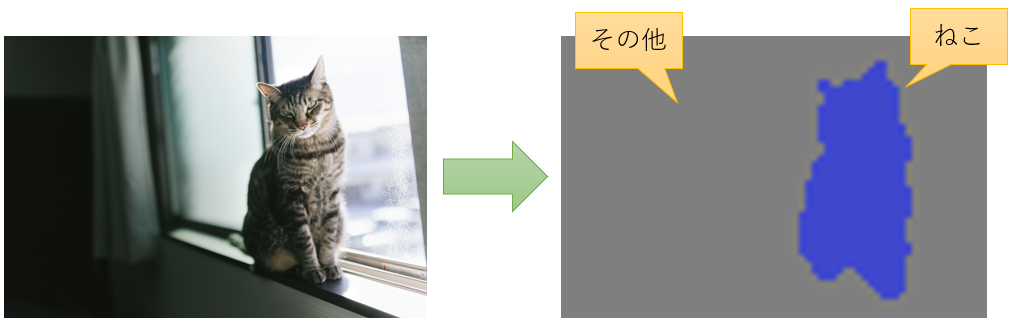
U-Netは元々、セマンティックセグメンテーション用に考案されたネットワークです。セマンティックセグメンテーションは画素ごとに何を表しているか分類するタスクですが、分類ではなく回帰にすることで画像を予測することができます。
セマンティックセグメンテーションの例
作成したモデルはこちら。
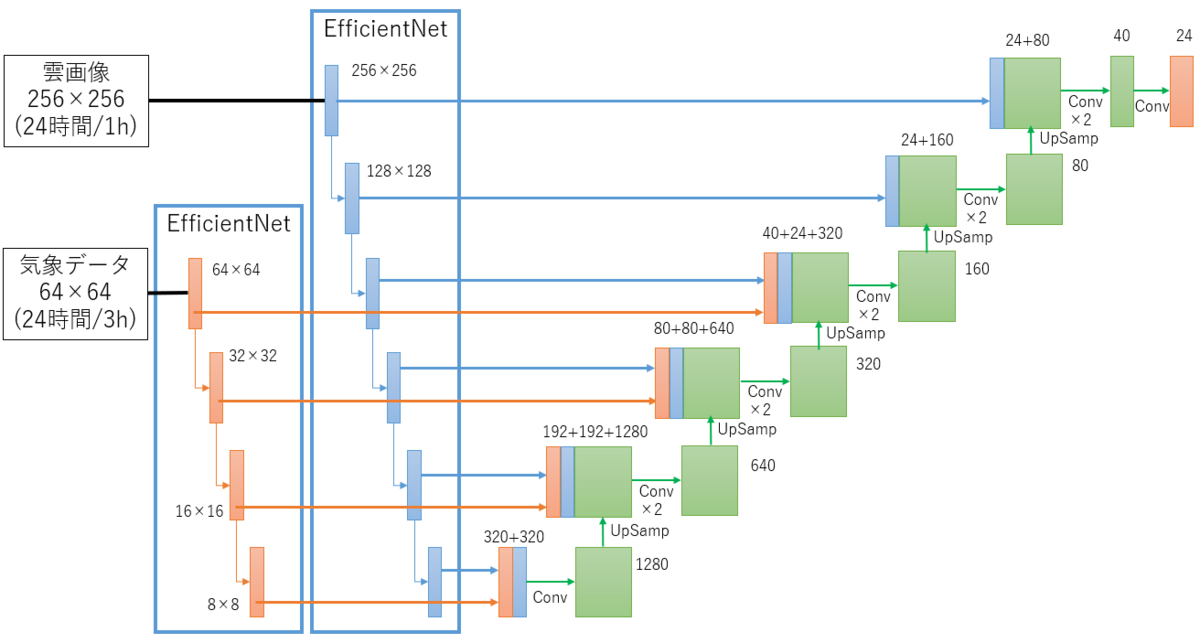
“U”の形に見えるからU-Netなのですが、Vっぽいですね。(図の書き方のせいです)
それはさておき、オリジナルのU-netとの大きな相違点は、エンコード(データのサイズを小さくしていく方)にEfficientNetを使っていること、雲画像と気象データのそれぞれに別のエンコーダを使用していることです。
EfficientNetとは、2019年に発表された画像認識モデルです。高精度かつパラメータが少ないことが特徴です。これを選んだのは、ただ単純に精度が高いと話題になっていたからです。
雲画像と気象データを別のエンコーダにしたのは、データサイズを変えたかったからです。気象データは元々34種類のデータになっており、私の場合は風のデータを正負で分割して51種類のデータになっています。つまり、雲画像と気象データを同じサイズにしたときに、気象データは雲画像の51倍と比較的大きなサイズになります。雲画像は高解像で、気象データは縮小して扱いたかったため、別のエンコーダにしました。それぞれのエンコーダの中間表現をデコーダに連結しています。
[学習時のパラメータなど]
・Optimizer:Adam
・Learning Rate:0.01でスタート、epochが5,20,40,50のタイミングで1/2にしています。
・Loss:L2(MSE:Mean Squared Error)
・Batch size:20
・Epoch数:100(ただし、EarlyStoppingをかけています)
・欠損データの扱い:雲画像の欠損データは使用しない。気象データの一部欠損データはチュートリアルの方法で補間。
・データ拡張:なし
・アンサンブル:なし
入賞したモデルは優秀?
さて、上記のモデルを実現して評価データを提出したところでタイムアップになったため、入賞するほどの優秀なモデルを作れたという実感はありませんでした。そこで、他のモデルと比較してみることにします。
比較の場はSIGNATEの「【SOTA】Weather Challenge:雲画像予測」です。ここでは、昨年度実施された、本コンペとほぼ同内容のコンペに挑戦することができます。異なるのは評価方法(こちらはMAE(Mean Absolute Error))のみであり、本コンペと比べて評価値の優劣は大きく変わらないはずです。ちなみにMAEでは評価値が小さいほど精度が良いということになります。
それでは、比較するモデルを紹介します。
① 本コンペで使用したモデル
② 2年分のデータで学習した、①と同モデル (①はミスで1年分でしか学習していませんでした)
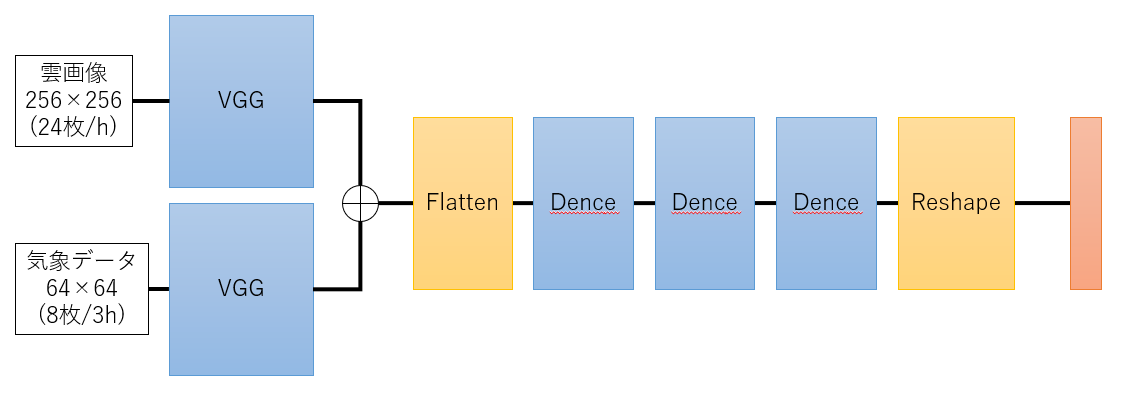
③ エンコーダはVGG、デコード部分を全結合層にしたモデル(雲画像のみ)

④ ②に気象データを追加したモデル
⑤ ConvLSTMを利用したモデル(64×64サイズ)
⑥ ConvLSTMを利用したモデル(128×128サイズ)
※ ConvLSTM:畳み込み(Conv)と過去の情報を引き継ぎながら学習するLSTMを組み合わせた手法。本コンペで2位の方が使っています。
結果はこうなりました。
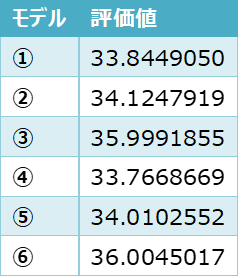
大きな差は開きませんでしたが、①は2番目の成績でした。
順位で見ても当時のコンペに参加していたらブロンズメダル(入賞)の範囲、そこそこ優秀のようです。
精度を上げてみる
入賞してもおかしくない精度だということはわかりましたが、時間があればさらに順位を上げることができたのでしょうか?
モデルを改良して試してみます。
[出力関数と損失関数の変更]
まずは、出力関数を恒等関数からHard Sigmoid関数、損失関数をMAE(Mean Absolute Error)に変更してみます。
Hard Sigmoidにしたのは、出力値に上限下限を付けることによって、出力がプラスやマイナスに大きくなりすぎても損失が大きくならないようにするためです。loss関数を変えたのは、MSEだと学習が進んで正解との差が少なくなった時に学習が進みにくいということが精度に影響を与えていると考えたためです。
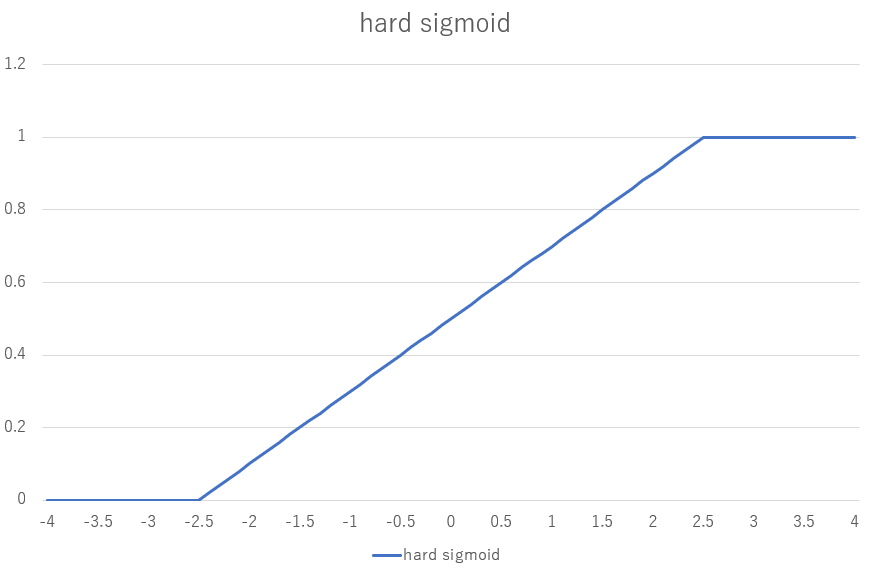
Hard Sigmoidのグラフです。出力を0~1にしてくれます。
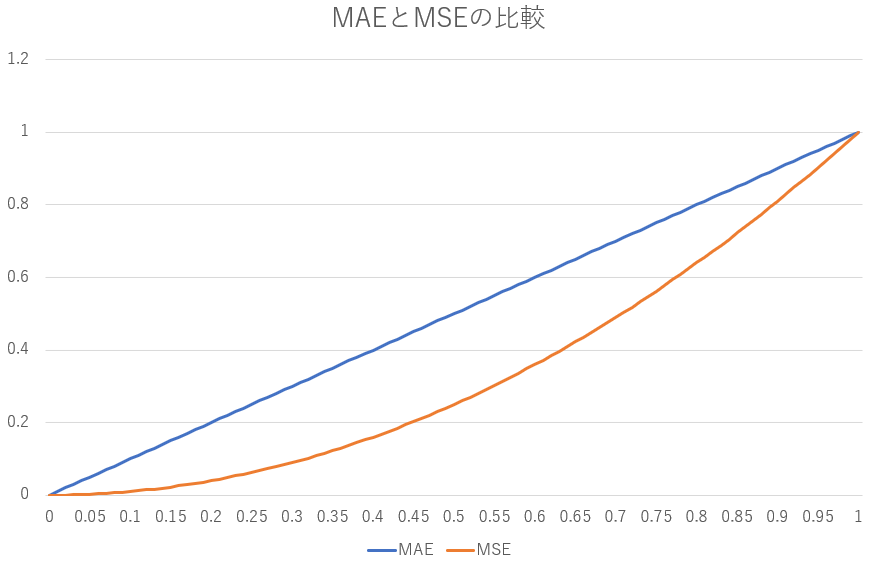
MAEとMSEの比較です。正解との誤差が小さくなるほど、MAE/MSEが大きくなります。
評価値:34.3338917
評価値が悪くなってしまいました・・・。
[クロスバリデーション]
ここまでは、学習データの一部を検証データとして使うホールドアウト法で学習させてきましたが、クロスバリデーションを試してみます。クロスバリデーションでは学習データを任意のグループに分割し、分割された1つのグループを検証データ、それ以外のグループを訓練データとします。そして、検証データとするグループを変更しながら学習していきます。学習データが少ないときに有効と言われる手法です。
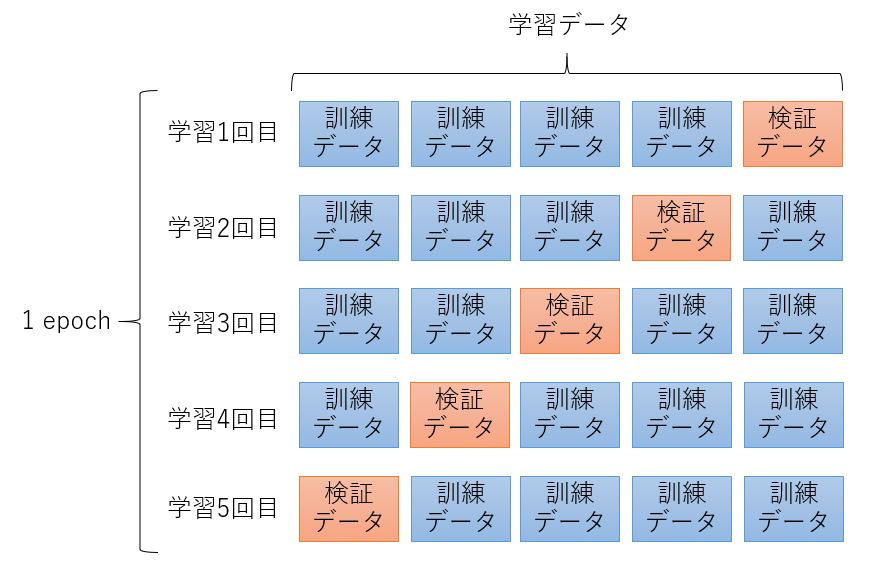
5分割のクロスバリデーションの例です。
評価値:33.6962375
評価値が良くなりました。
[モデルの変更]
いろいろとモデルをいじって試してみましたが、一番良かったのは下記の変更をしたモデルでした。
・ 雲画像は128×128(直前の1時間)、64×64(24時間/1h)、32×32(90時間/2h) 、気象データは128×128(直前の1時間)、64×64(24枚/3h)、32×32(90枚/6h)をそれぞれ別のエンコーダに通す。
・ デコーダでの16×16、32×32、64×64の特徴マップを拡大して128×128の特徴マップと連結させる。
・ 64×64と32×32の画像も出力する。(小さい画像からも学習する)
変更後のモデル(デコーダ部分のみ)
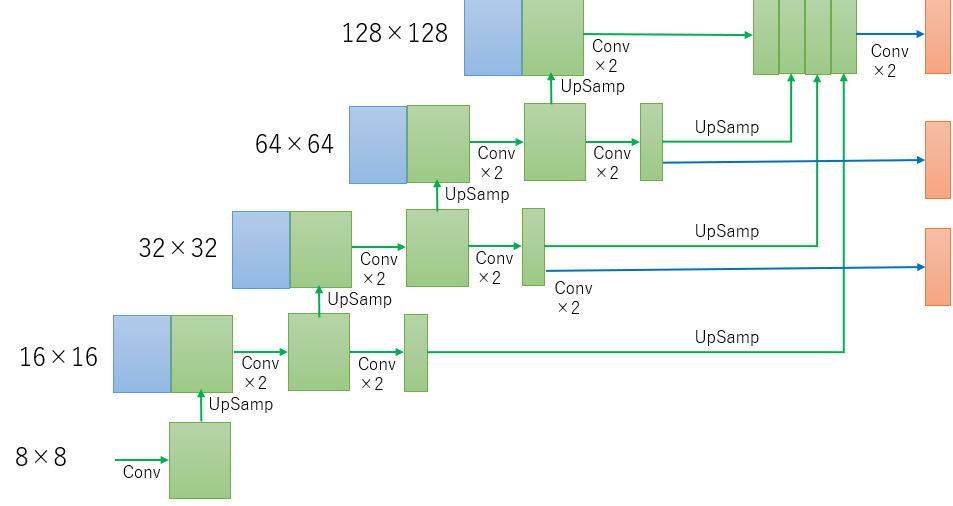
このデコーダの変更には、64×64、32×32の画像から時系列の情報を学習して128×128の画像に伝えたいという意図があります。
評価値: 32.0328337
[損失計上箇所の変更]
評価値を下げることはできましたが、順位を変えられるほど下げることはできませんでした。
コンペ上位の方の解法と大きく違うことは無いはずですが、最上位は評価値約25です。ここまで評価値が違うのはどうも腑に落ちません。
と、ここであることに気付きました。
評価は、画像の一部分で行いますが、損失の計算は画像全体で行っています(評価部分は全体の約40%)。画像全体の精度を上げようとしているため、評価箇所の精度が思うように上がらないということなのかもしれません。「学習データと同範囲の雲画像を24時間分予測する」ことが必須要件であったため、評価箇所だけを損失として計上することは反則(主催者の意図に沿っていない)だと思っていましたが、評価箇所を絞っているということは、評価箇所が本当に予測したい箇所だと考えることもできます。
ということで、損失を評価箇所に絞って計上してみます。
評価値: 33.5591247
悪くはないですが、劇的に改善されたわけではありません。どうやら過学習しているようです。
思うように評価値が良くなったわけではありませんが、実際の評価方法と損失の計上方法が近づいたため、検証データでの評価がしやすくなりました。検証はここまでにしますが、ここからまたモデルを変えていけば評価値を良くできる気がします。
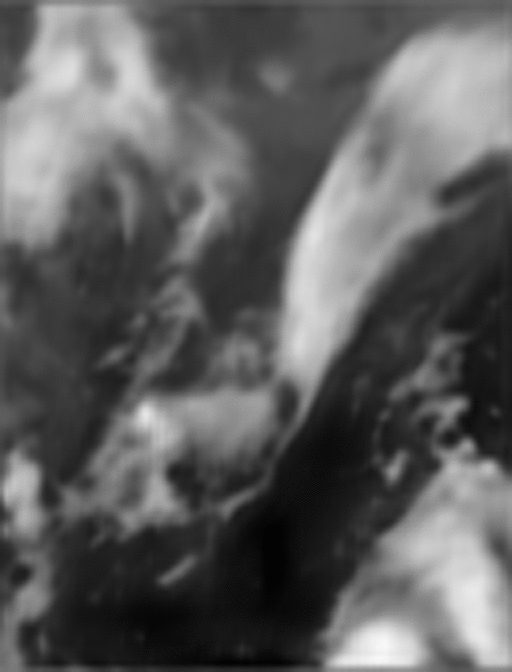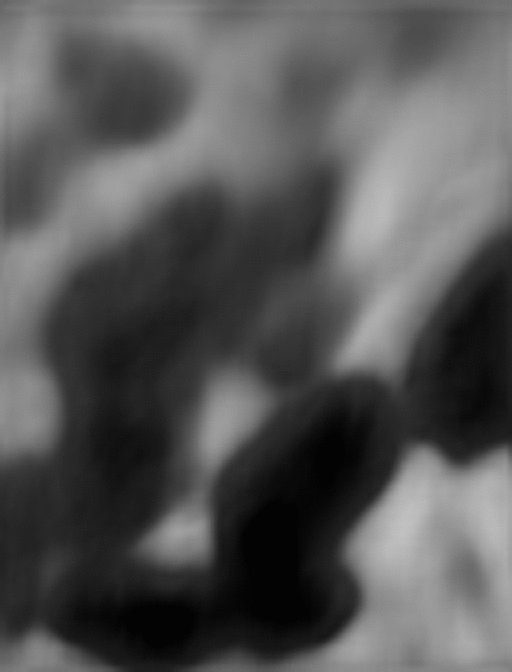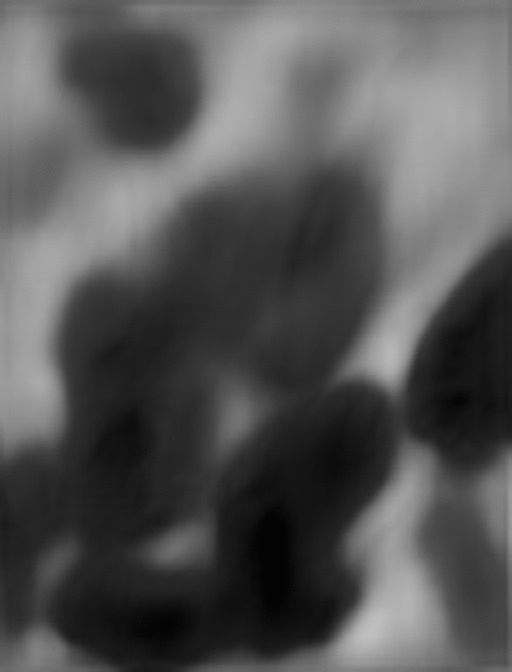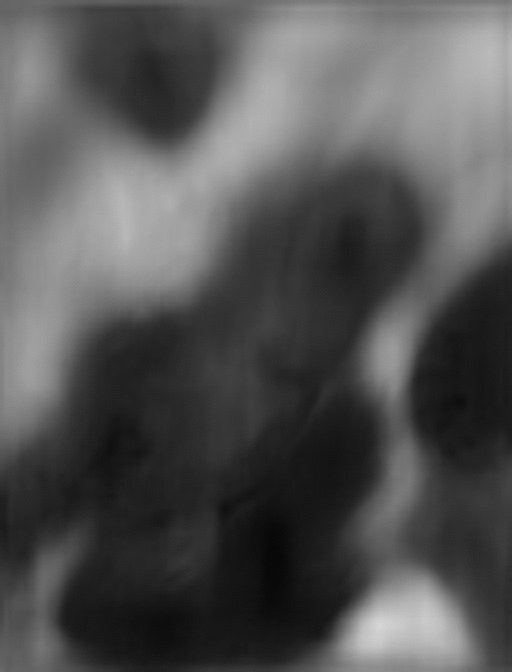
最後のモデルで予測した雲画像はこちらです。
評価値からすると雲の動きは正解と差異がありますが、雲の流れを上手く表現できているように見えます。
まとめ
検証の結果、
①入賞したモデルはそれなりに優秀だった
②時間があれば精度を上げる余地があった
ことがわかりました。
とはいえ、まだまだ上の人がいることも事実です。また記事にできる成果を出せるよう、気を抜かずに勉強に励みたいと思います。
コンペティションの企画・運営、データを提供してくださった、日本ディープラーニング協会、SIGNATE、株式会社ウェザーニューズの皆様、ありがとうございました。